Our genome is an ocean of DNA sequences, some are useful, some are not, some are repetitive, some are not, and some can make differences while some can’t. There are 3.2 billion base pairs present in our genome.
It takes 2,329,000 pages to write all the nucleotides present in our genome, imagine how huge it is! The prime function of our genome is to store, transfer and express genetic information.
Scientists broadly divided the human genome into coding and noncoding parts. This article is all about coding and non-coding DNA. Let me first clarify that this is a ‘kind’ follow-up article for our previous article Gene vs DNA. I have clearly explained why. A gene itself is DNA thus, it is not worth comparing them.
In this article, I will explain my point which is the difference between coding vs non-coding DNA. Both are the type of DNA but have significant differences in terms of functionality and localization.
Stay tuned.
Disclaimer: Information provided here is collected from peer-reviewed resources and re-presented in an understandable language. All the sources are enlisted at the end of the article.
Coding vs non-coding DNA:
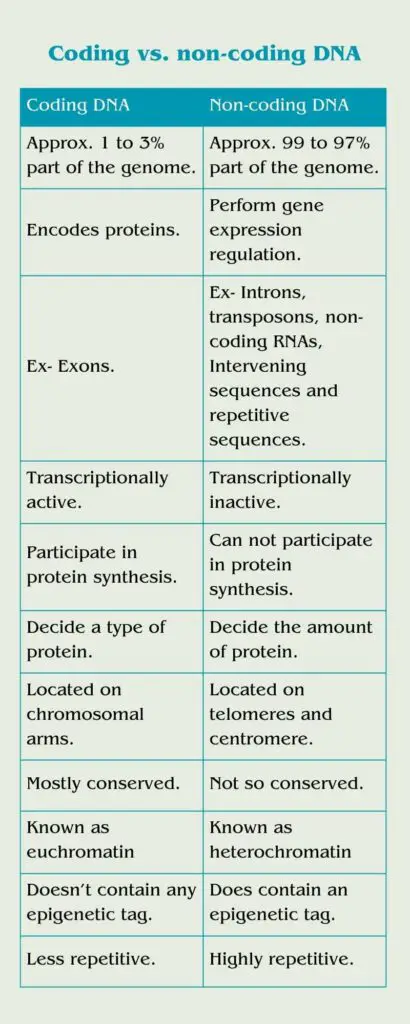
The coding part of our genome can encode proteins while the non-coding part participates in the regulation of gene expression.
Approx. 1 to 3% part of our genome is coding and known as genes while the rest of 97 to 99% part is known as non-coding DNA. Previously, it was referred to as junk DNA, as the non-coding part can’t participate in protein synthesis. However, later on, its role in gene expression regulation was established.
Related article: Junk DNA– Definition, Structure, Function and Examples.
Myth busted!
Non-coding DNA can be called ‘Junk’ but is functional as well. Non-coding and coding both parts have crucial functionality.
At a molecular level, a gene is made up of regulatory elements, a promoter, introns and exons. Only exons are coding sequences while regulatory elements, a promoter, introns and intergenic sequences are non-coding DNA. Other non-coding DNA are transposable elements, telomeres, repetitive sequences and pseudogenes.
Coding DNA participates in replication, transcription and translation and produces a DNA copy, mRNA transcript and a protein, respectively. The non-coding DNA does participate in replication and but not in transcription and translation.
It produces a DNA copy but can not transcribe into mRNA and thus can’t produce a protein. Instead, it produces various types of non-coding RNAs and participates in gene expression regulation. Note that some genes may transcribe into mRNA but can’t produce proteins.
So technically, the coding part has the right to control the process of ‘which protein to produce’ while the non-coding part has the right to control the process of ‘in which amount that particular protein can be produced.’
Now coming to the crucial point of this article– The location!
Coding sequences— Exons are crucial for manufacturing traits and thus will remain conserved, most of the time. Mutation or any other sequence alteration results in loss of gene function, or production of abrupt or truncated protein.
So, although both are located on the chromosomes, the coding sequences are located on the chromosomal arms either ‘p’ or ‘q’ arms while the non-coding DNA is located on either telomere or centromere, majorly.
The reason is, (I’m going so deep into this topic, I hope you are enjoying) replication oftentimes poorly replicates or fails to replicate chromosomal ends and repetitive DNA. So if such crucial genetic elements (coding sequences)are located on ends and miss replication, they can’t be inherited correctly.
If it will be there in the middle of the chromosomes (on arms) where the replication process is at its peak! It can accurately be replicated and inherited.
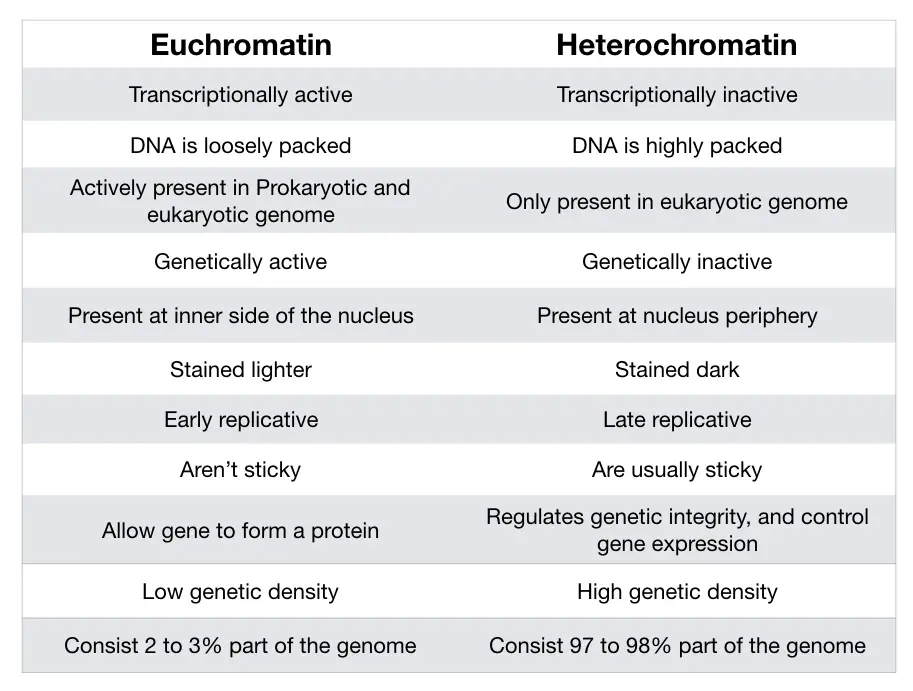
The coding portion is known as an euchromatin region while the non-coding portion is known as a heterochromatin region. Both regions have indeed different characteristics, so I published an amazing article on this topic. You can read it here.
Euchromatin vs Heterochromatin.
Here comes another important point— the epigenetic tag!
Methylation, acetylation, histone modification, etc are common epigenetic tags that, when incorporated into a sequence, make it transcriptionally inactive. Coding DNA does not contain any epigenetic tag while the non-coding DNA does contain any epigenetic tag.
Thus, coding sequences are transcriptionally active while non-coding DNA is transcriptionally inactive. I explained these things more comprehensively in our previous article, the link is given above (Euchromatin vs heterochromatin).
Coming to the last point of this topic— the function!
Coding parts synthesize various proteins and control traits like metabolism, reproduction, development, and eye and skin color while the non-coding parts work as a supportive or simultaneous mechanism that not only helps coding DNA but also regulates traits or phenotype expression.
For example, the OCA2 gene regulates eye coloration traits (coding part) while the non-coding DNA helps regulate the amount of eye coloration depending on the requirement.
Wrapping up:
In conclusion, we can say both genomic entities are dependent on each other; coding regions require promoters and regulators like non-coding sequences for protein synthesis while the non-coding DNA requires transcribed mRNA for regulation of gene expression.
Thus, the present comparison proves the point that both types of genomic entities have significant functions and roles in genome stability and gene expression. I hope now the point is clear, why the comparison between coding vs non-coding DNA is worthwhile but not gene vs DNA.
Sources:
Non-coding DNA— A brief review by Anandkumar S and Arumugam N et al.