“The information present in DNA in the form of A, T, G and C nucleotides which construct or translate a protein is known as genetic code. Three out of the four nucleotides form a single unit to make amino acids.”
We know everything about DNA, right! Because, for that, we have created this blog. Go, check out this article for more detail: DNA: Definition, structure, function, and various types.
One kind of nucleic acid- DNA is a long chain, a biomolecule, and a basic unit of our life, whose major function is to store and transfer information.
We can say, without DNA, or information encoded in it, new life can’t form. The chain of it is made up of monomer units of nucleotides. Nucleotides are joined together by the phosphodiester bond and form the long DNA chain, which we call a polynucleotide chain.
Purines and pyrimidine- nitrogenous bases are the foundation of nucleotide along with sugar and phosphate.
A, T, G and C are those four bases in which all the information of all life forms on the entire earth is encoded. And therefore it is important.
Why it is known as “genetic code?”, is our DNA on some secret mission?
Until the DNA can’t undergo translation, the information encoded in the four letters can’t be expressed.
There is a special assembly and setup in our cell to decode the information and form proteins, known as the ‘process of central dogma’. The replication, transcription, and translation are combinedly known as the processing unit or central dogma of a cell.
Remember, DNA has two main functions; to form a protein and to regulate gene expression, nothing else.
Now, let us briefly understand what the trio does do for us in a cell.
Replication is a process of doubling the DNA, the exact same copy of DNA forms which inherited in other cells.
Transcription is a process in which an mRNA is formed from a gene having the only coding sequences. The mRNA is an intermediate nucleic acid sequence that migrates to the cytoplasm to translate.
The translation is a process in which a protein molecule is manufactured in the cytoplasm from the mRNA.
Some non-coding DNAs, we know it has junk- DNA helps in gene regulation. In which amount a particular gene expresses or constructs a protein. Surprisingly, we yet not mentioned the genetic code and what it is.
The above information is basic, you need to understand before understanding our present topic. In the present article, we will talk about the codons, genetic codes, and how it works. Furthermore, we will explain to you tabularly how the codon forms various amino acids.
Related article: What is a gene?
So let’s start the topic.
Key Topics:
What is the genetic code?
I will try to explain to you in plain language, information coding and decoding process is governed by transcription and translation, collectively control gene expression.
During the transcription, the information present in a DNA (in the form of a gene) “rewritten” into the mRNA which is the readable form of information for the ribosome.
Afterward, the mRNA reaches to cytoplasm and “decodes” the information in the form of amino acid. In this coupled process, some mRNA makes protein and some can’t and regulates the expression of genes.
The information present in the nucleotide sequence of a gene is known as genetic code, each triplet of if creates an amino acid. Likewise, all the amino acids of a protein manufactured.
A key element of genetic code:
Only a specific gene sequence can make a protein, change in it can’t do this. Therefore the genetic code of a gene should be unchanged or unmutated.
Definitions:
“A set of rules, a cell uses to forms proteins is known as genetic code.”
Or
“Information in a DNA in the forms of A, T, G, and C used to form or translate into amino acids is known as genetic code.”
“Genetic code is a set of three nucleotides (known as codon) having information for an amino acid, start or stop signal.”
History:
The idea of codon theory was given by Francis Crick who was one of the scientists who discovered the structure of DNA. But the actual concept of the tripled codon from which 20 various amino acids are formed had given by Soviet-American theoretical physicist George Gamov.
He postulated that the combination of three codes of four bases forms 64 different combinations or permutations of amino acids. We will explain to you the two codes and three codes hypotheses later in this article.
Although, after Gamov’s demonstration, the actual experimental representation of a codon was explained by Crick, Brenner, Barnett and Watts T.
In 1961, Nirenberg M and Matthaei J had relieved the triplet nature of codons. Soon after, an India Scientist Har Gobind Khorana had identified the rest of the genetic codes which Nirenberg and Matthaei fail to explain. Finally, in 1968, Nirenberg, Har Gobind Khorana, and Robert W. Holley were given Nobel prize in Medicine for finding and explaining genetic code.
Properties of Genetic code:
Genetic code is a triplet:
As described by Gammow the genetic code is made up of the three nucleotides and forms 64 different combinations. A single triplet is a codon.
Universal:
The genetic code is universal which means it is present in all organisms on earth. What amino acid a triplet forms in one organism, the same amino acid it forms in all organisms.
Starting from single-cell prokaryotes to eukaryotes, all life has the same kind of genetic codes. All living organism forms all their 20 amino acids from these 64 permutations of a codon.
Also, the start and stop codons are universally present in all.
The genetic code is highly degenerate:
DNA has 4 letters and code has a triplet of it which means 64 different combinations can be possible. But only 20 different amino acids are existing. Which literally means that more than one codon is for a single amino acid. For example, the proline is translated from 4 different codons viz, CCU, CCC, CCA, and CCG.
Notably, AUG and UGG are the only two amino acids that encode only a single amino acid.
The genetic code is non-overlapping:
A single code encodes only a single amino acid which means, It can’t be shared to form another amino acid. I know it’s a bit confusing. See the image below, it helps you to understand well.
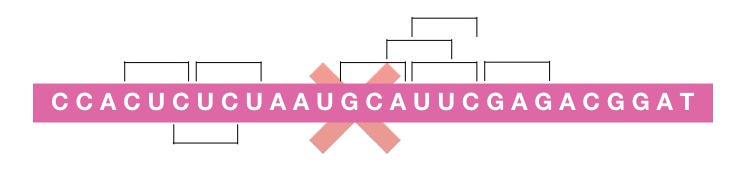
The code is unambiguous:
This means that a genetic code or a single codon always forms an amino acid whenever it undergoes transcription. Also, it can’t form another different amino acid.
The code is continuous and comma less:
A chain of genetic codes or codons is written in a single continuous line without any comma. No lines or any indication can be allowed in an mRNA chain. See the image below,

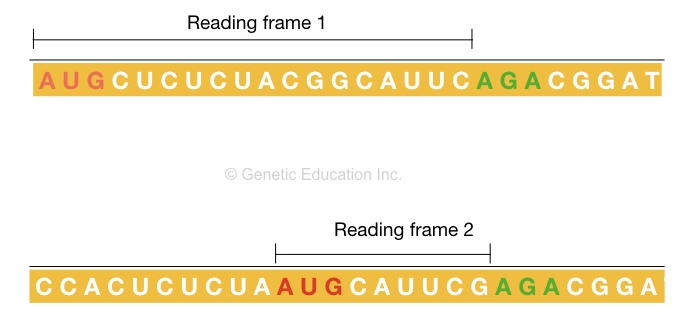
The reading frame:
Defining a reading frame is quite difficult because it is just a concept to dictate the translation process and how different protein forms. First, see the image below,
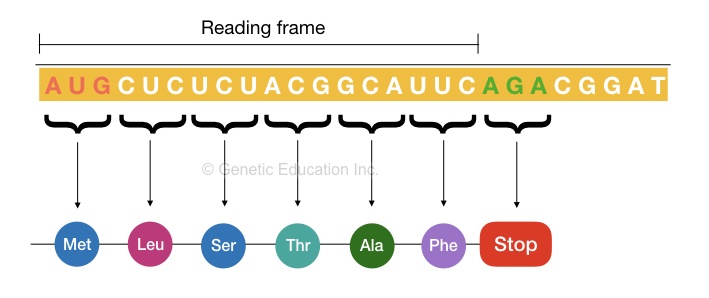
The reading frame determines the order of mRNA from which a protein is formed. Every reading frame starts with the AUG start codon and then expends to the end codon. Every reading frame starts with the AUG.
The thumb rule to read the reading frame is that it should be read from 5’ to 3’ direction from the start codon. However, in eukaryotes, the open reading frame sequences (exons) are interpreted by the introns which are removed during the mRNA synthesis.
“The sequence starting from the AUG (start codon) and stop codon which translates into protein is known as a reading frame.”
Start codon:
A genetic code is initiated by the defined three-nucleotide codon known as the start codon from where the translation initiates. The AUG is one of the most common start codon present in all organisms.
Unlike the stop codon, the start codon AUG encodes for the amino acid methionine. Besides, GUG and UUG are also found in some organisms as a start codon which encodes valine and leucine amino acids, respectively.
The translation process always starts with the AUG, so the first amino acid in a polypeptide chain should be a methionine, however, it is not always a case, the Methionine is removed or snipped off from the final amino acid chain, if not needed.
Stop codon:
A type of codon, unlike the start codon and amino acid codons, the stop codon gives a signal to stop the translation of protein. Usually, three stop codons are present named ‘amber (UAG)’, ‘opal (UGA)’ and ‘ochre (UAA)’.
The names don’t define the properties of any stop codon, nonetheless. There is a small story behind it.
Researcher Epstein R and Steinberg C had given the name “amber” to one of the stop codons from their friend’s name (Bernstein H) which means amber in German. These two had discovered the stop codons.
The stop codon is also known as a nonsense codon. If it is inserted into the DNA sequence prematurely, it creates mutations. Conclusively, the stop codon in the mRNA gives a signal to detach from the ribosome assembly. A truncated protein forms.
Codon redundancy:
The genetic code follows the mechanism of redundancy means, different codons form a single amino acid but a single codon can’t take part in the formation of different amino acids. However, a sequence can be read differently depending upon the location of the start codon. See the image below,
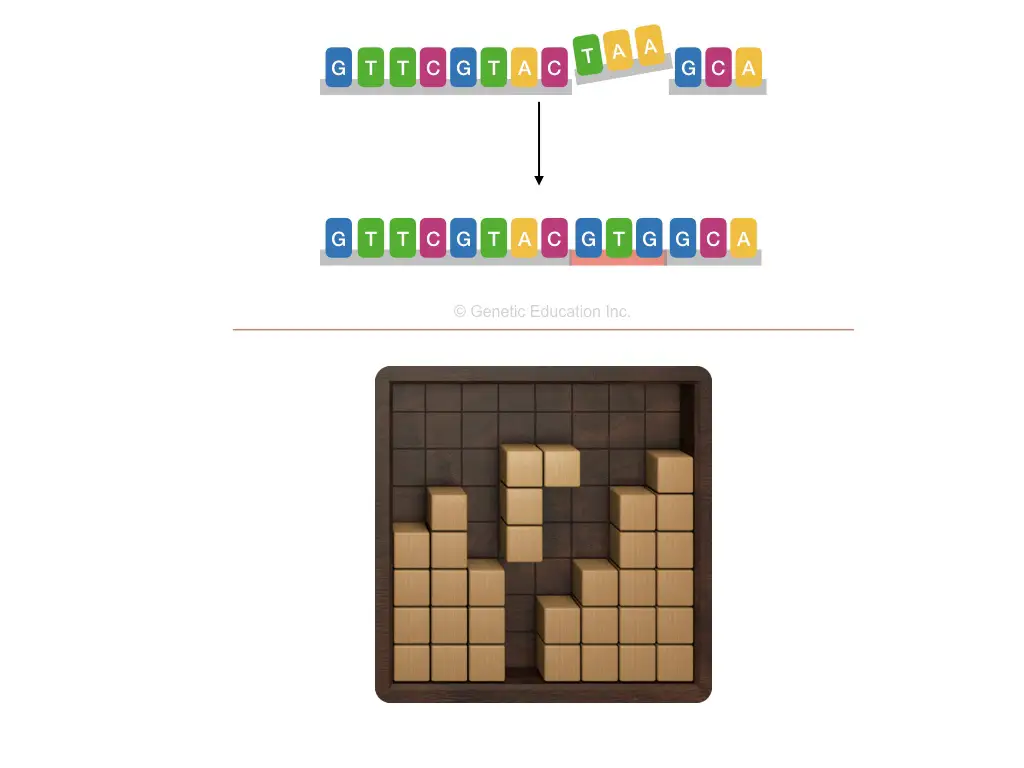
Mutations and genetic code:
Mutations are the greatest things to induce new alterations in nature. Three of the common genetic mutations viz point mutations, missense mutations and non-sense mutations can change the genetic code.
You must have played the game of arranging the block! Right! If you put a wrong block, it can’t fill the gap. That exactly the mutation is! If any wrong base incorporated into the sequence of a gene, a protein can’t be formed.
Change in the sequence of a gene or DNA which alters the protein formation is known as mutation.
The classic example point mutations are sickle cell anemia, cystic fibrosis and thalassemia. A single base change in a beta-globin gene causes serious anemia.
Here, due to this change, the amino acid formed by the reading frame can’t form properly, and thus a beta-globin gene involved in the hemoglobin construction, can’t form properly. And the resulting consequences we know.
Another mutation of the class point mutation is the “missense mutation”. In this type of mutation, the codon translates entirely different amino acid, means, forgets its sense to form amino acid.
The non-sense mutation is also a type of point mutation, besides. In the point mutation, the stop codon is added prematurely during translation and thus a truncated protein formed.
The reasons behind occurring the mutations are either intrinsic or extrinsic factors. Replication error and DNA breakage are intrinsic while UV light, high temperature and radiations are the extrinsic factors that cause mutations.
If you are very much interesting to read more on mutations, read this article of our’s: Genetic mutations: Definitions, types, and causes.
During replication, in every 100 million bases, the polymerase inserts a wrong base. However, thanks to our DNA repair system, almost all the errors are repaired at last.
Doublet vs triplet code theory:
The mathematical explanation of the triplet code theory was given by Gamow G. As we discussed elsewhere in the article, the triplet codon combination can make 64 different combinations of the codon for 20 different amino acids. But that is not possible by doublet!
In doublet- 2 nucleotide code per amino acid, it can able to make only 16 possible combinations for 20 different amino acids. And as we know that codes can’t overlap, doublet codon theory can’t be possible to code for all 20 amino acids.
Therefore, the triplet codon theory suite more appropriately for the genetic code.
4 (possibilities for the first slot) * 4 (second slot) * 4 (third slot)= 64.
Gamow G’s findings were mathematical, yet, there was not any scientific or experimental base behind it. However, Nirenburg had started working on Gamow’s triplet codon hypothesis during 1961. A glimpse of their experiments is given here.
Nirenburg had artificially synthesized mRNA only having uracil in it (poly-U). He had taken a cell-free system of E.coli to translate protein and added the poly-U mRNA into it.
His results indicated that only phenylalanine was formed exclusively and conclusively (UUU encodes for phenylalanine). Similar experiments had performed on with the poly-C mRNA and results had shown that only proline was formed.
He finally concluded that the UUU might encode for phenylalanine while CCC might encode for proline.
Later on, the rest of the amino acid codes were identified and discovered by Gobind K using the same experiment of Nurenburg.
Genetic code chart:
In this section, we are explaining how to read the genetic code chart. Take a look at the chart below,
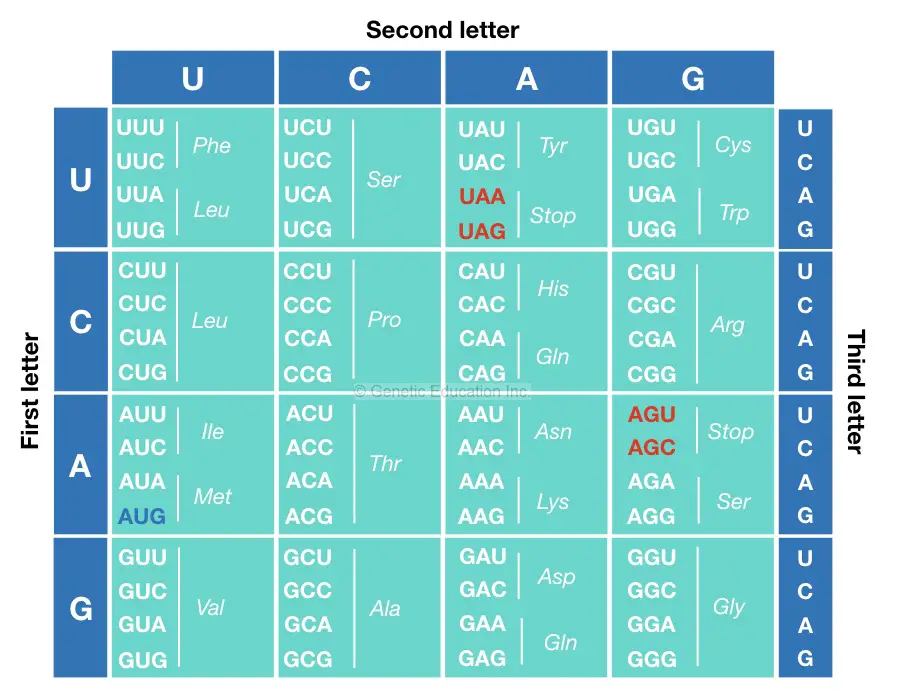
As we explained above, to construct a codon chart, Put all four nucleotides one by one on all three positions as shown in the chart.
Here in the table, The blue code “AUG” is a start codon while the red one are the stop codon.
Summary (quick learning):
A genetic code is a triple nucleotide combination having information to make amino acid.
A gene is a long chain of nucleotides that translates into mRNA, which is a readable form. A group of three nucleotides of mRNA is a “codon” having information to code for an amino acid.
The genetic code is universal, continuous, unambiguous, and non-overlapping. Furthermore, the reading frame makes a dedicated protein with a start and stop codon.
AUG start codon recognizes as a starting point while the translation ends once it reaches to one of the stop codons. The stop codon can’t form any protein.
Conclusion:
A genetic code is a blueprint of our biological information. Thus it is very necessary to protect it from mutations and other alterations, although we can’t protect it from biological forces by quitting smocking and tobacco, we can prevent so many carcinogenic mutations.
Eat healthy food and stay away from the factors that damage your genetic profile.
Sources:
- Griffiths AJF, Miller JH, Suzuki DT, et al. An Introduction to Genetic Analysis. 7th edition. New York: W. H. Freeman; 2000. Genetic code.
- Sleator RD. The genetic code. Rewritten, revised, repurposed. Artif DNA PNA XNA. 2014;5(2):e29408.